
Novel View Synthesis (NVS) aims to generate images of a scene from viewpoints that were not originally captured. Given a set of reference images and their camera poses, the goal is to synthesize a realistic image from a new camera position. This is an important problem in computer vision with applications in 3D reconstruction, robotics, virtual reality, and generative modeling.
Many recent approaches rely on explicit 3D scene representations such as Neural Radiance Fields (NeRF) or 3D Gaussian Splatting. In contrast, the Large View Synthesis Model (LVSM) proposes a different approach: instead of reconstructing an explicit 3D representation, it directly predicts new views using a transformer conditioned on reference images and camera information.
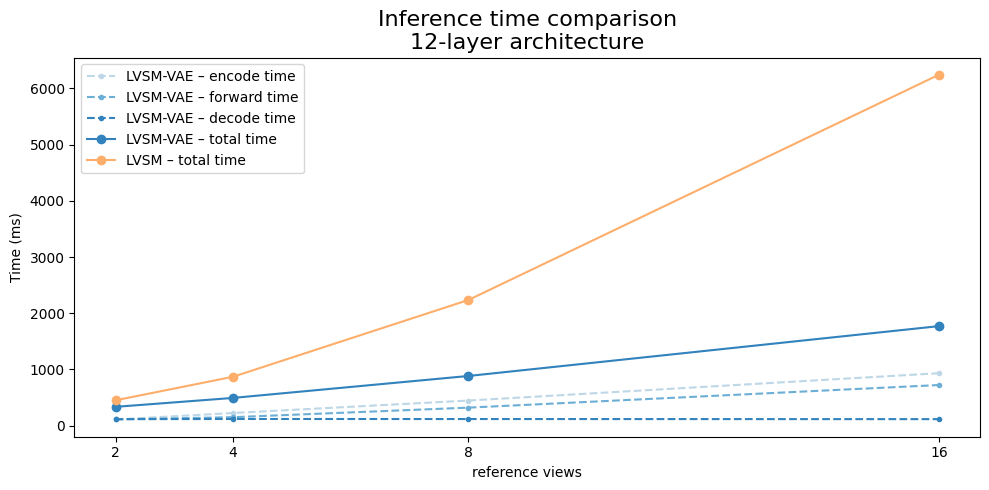
While LVSM produces high-quality results, it is computationally very expensive because it operates directly in pixel space. Training and inference therefore require large amounts of GPU memory and compute.
In this project, we explore a more efficient formulation of this idea by introducing LVSM-VAE, a variant of LVSM that performs view synthesis in the latent space of a Variational Autoencoder (VAE) rather than in pixel space.
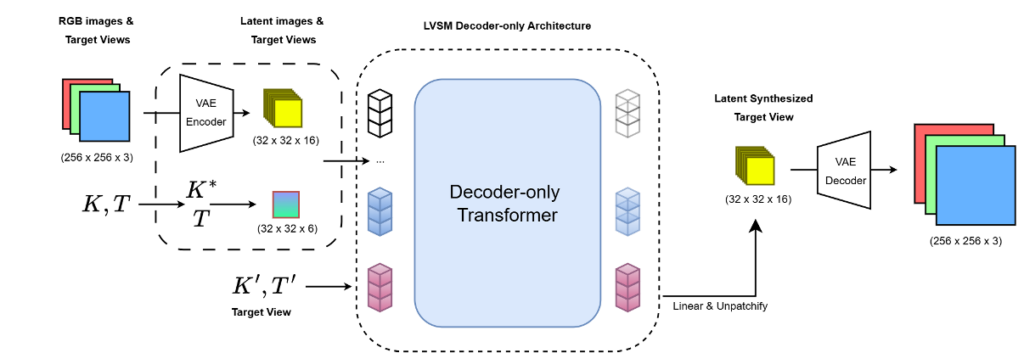
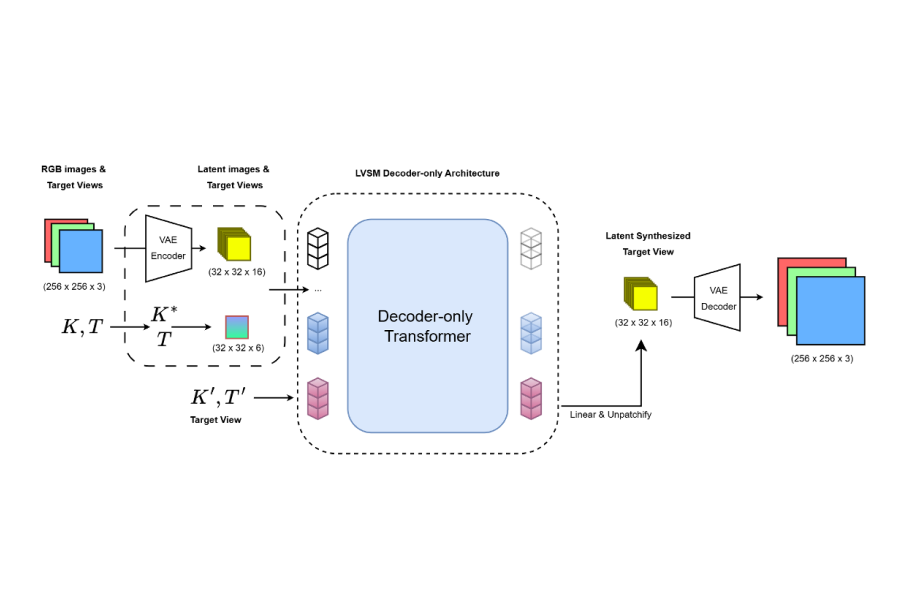
The main idea is to first compress input images into a lower-dimensional latent representation using a pretrained VAE. The transformer model then operates on these latent features instead of raw pixels. After predicting the latent representation of the target view, the VAE decoder reconstructs the final RGB image.
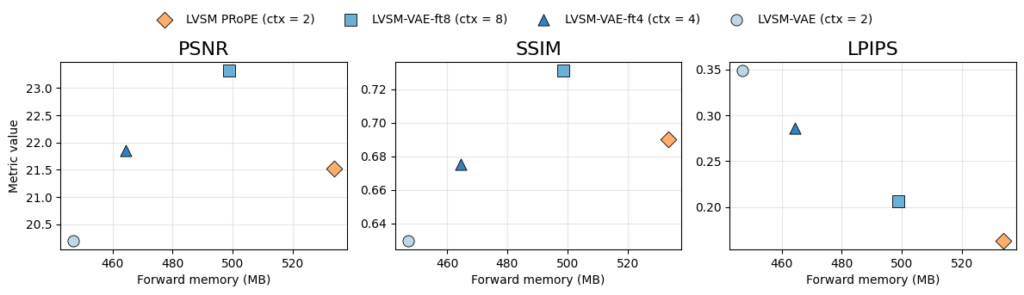
Because latent representations are spatially smaller than the original images, the transformer processes significantly fewer tokens. This reduces both memory consumption and runtime while maintaining the flexibility of the original LVSM architecture.
The model still uses the same core components as LVSM: image patches, camera pose information, and ray embeddings derived from camera intrinsics and extrinsics. However, since the images are encoded into a compressed representation, the camera intrinsics are adjusted to remain consistent with the latent resolution. The transformer then predicts the latent representation of the novel view conditioned on the encoded context views.
Our experiments show that LVSM-style novel view synthesis can successfully be transferred into latent space, achieving competitive results while significantly reducing computational requirements during inference.
This page provides a high-level overview of the project. For detailed information about the dataset, training setup, experimental evaluation, results, and future work, please refer to the full report.
📅 2025
💼 Technical University Munich
🧔 Felix Laarmann & Jonas Fischer


